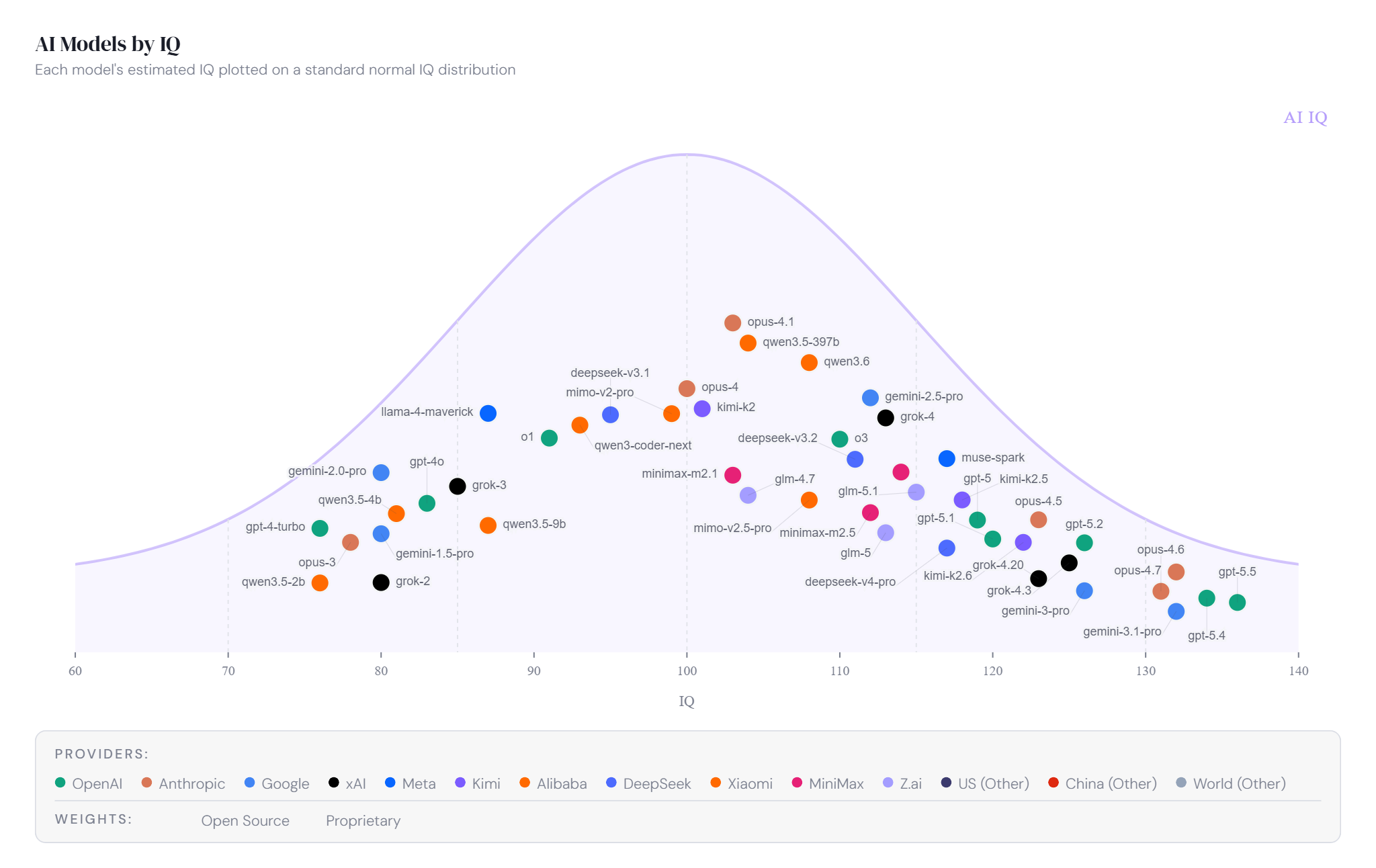
A site called AI IQ is doing something simple and controversial at the same time: it assigns IQ scores to more than 50 frontier AI models and plots them on a standard bell curve. Built by Ryan Shea, a Princeton engineer and co-founder of the blockchain platform Stacks, the project at aiiq.org pulls from 12 benchmarks across four reasoning dimensions: abstract, mathematical, programmatic, and academic. The composite score is a straight average of those four. As of mid-May 2026, OpenAI's GPT-5.5 sits at the top with an estimated IQ of 136, followed closely by Anthropic's Opus 4.7 and Google's Gemini 3.1 Pro. The gap between the leading models has never been tighter.
The site also scores emotional intelligence, mapping each model's EQ-Bench 3 Elo and Arena Elo scores into a composite EQ. Anthropic's Opus 4.7 leads that dimension with a score near 132. One notable detail: EQ-Bench 3 is judged by Claude, an Anthropic model, so the site applies a 200-point Elo penalty to all Anthropic EQ-Bench scores to correct for the obvious conflict. The cost-performance chart may be the most practically useful feature, showing that models like DeepSeek-V3.2 and GPT-5.4-mini deliver IQ scores in the 112 to 120 range at a fraction of the cost of top-tier options.
Critics argue the entire framework collapses something irreducibly complex into a number that feels more precise than it is. 'AI is far too jagged. The map is not the territory,' wrote one commentator on X, pointing to the well-documented phenomenon of models acing graduate-level physics while failing at tasks a child handles easily. Others flagged that the calibration curves are not published as open datasets, making full reproducibility impossible. AI IQ is not a perfect tool. But for anyone trying to compare models across providers without wading through a dozen self-serving benchmark tables, it is at least a starting point.



